


In the first post of this series, we explored why large language models (LLMs)—despite impressive capabilities—fall short for military and intelligence operations. These models are disconnected from mission-specific data, they age poorly, they hallucinate, and they aren’t designed for the security and operational demands of national security environments.
Retrieval-Augmented Generation with Reasoning (RAG-R) solves these problems without requiring you to build your own model from scratch or endlessly fine-tune an existing LLM. Let’s explore why RAG-R represents a fundamentally different approach to operationalizing generative AI.
Defining RAG: A separation of powers
Retrieval-Augmented Generation is a new way of using the models we already have. This method makes them viable for operational use by allowing for flexibility and the exploitation of new knowledge.
At its core, RAG is a simple concept. Rather than asking an LLM to know everything, its focus is trained on reasoning. The model becomes a synthesizer, not a knowledge base. It just needs to know how to interpret what it’s given—namely, updated information drawn directly from the authoritative knowledge sources the mission already uses.
When a user issues a prompt, the system doesn’t rely on the model’s training data. Instead, much like a human officer would refer to relevant source materials, the system searches a curated repository of relevant data. It retrieves the most pertinent sections. And then it injects them into the model as context. The model then formulates its response using only that information combined with structured reasoning techniques.
Four major advantages of RAG-R
Compared to relying solely on LLMs, this architecture introduces four game-changing advantages:
- Continuous updates without retraining. If new information is published, it can be added to data stores and becomes instantly available for retrieval. No months-long retraining cycles. No waiting for the next model version.
- Mission-specific knowledge control. Different AORs or enclaves can maintain their own tailored document sets, ensuring that users draw only from what’s operationally relevant and that models don’t hallucinate in their responses.
- Traceability. The model’s answers are grounded in specific documents or data stores, so those resources can be cited, audited and reviewed. When the model recommends a particular course of action, the operator can inspect which documents contributed to that recommendation.
- Mission-aligned security. RAG-R can be deployed inside classified enclaves while respecting access controls and need-to-know filters. It doesn’t require moving sensitive data out to a public cloud. And because the retrieval layer can be configured to index only approved documents, the system remains aligned with information governance policies.
The PB&J principle: Understanding chain of thought and web of logic
One of the more nuanced but absolutely vital reasons RAG is effective in operational settings is that it can be paired with structured prompting techniques that mirror the way national security professionals think. These techniques—chain of thought and web of logic prompting—serve as mental scaffolding for the model, guiding its reasoning along deliberate, mission-relevant paths.
Chain of thought is the simpler of the two approaches. Instead of asking the model to produce an answer immediately, we prompt it to reason through the problem step by step. This process of breaking tasks into phases, evaluating each part, and building a rationale on the go more closely aligns with human rationality and mimics how analysts and officers approach complex tasks.
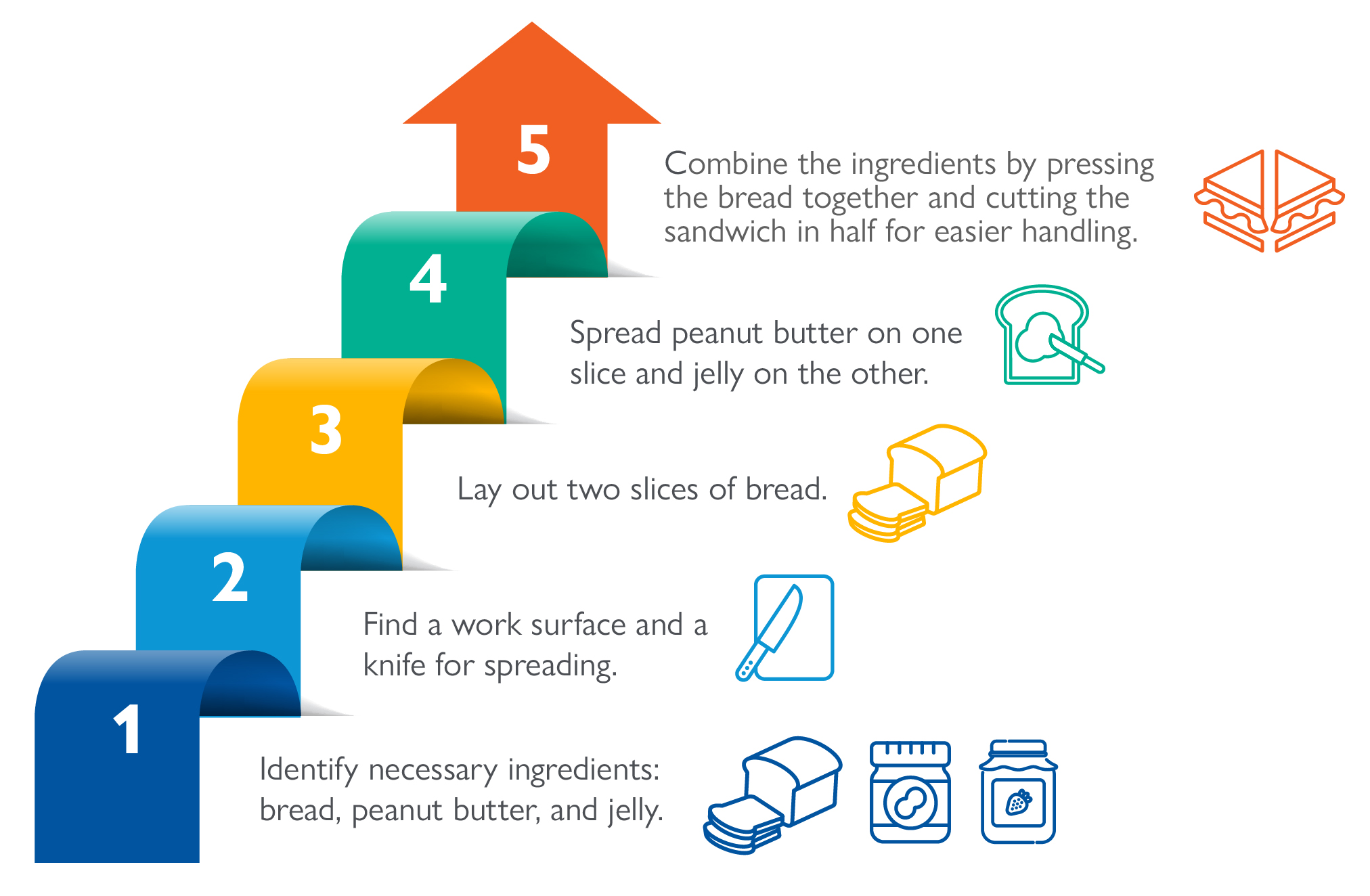
To illustrate this, think about making a peanut butter and jelly sandwich. A chain of thought approach would involve these steps:
Figure 1. Chain of thought prompting
- Identify necessary ingredients: bread, peanut butter, and jelly.
- Find a work surface and a knife for spreading.
- Lay out two slices of bread.
- Spread peanut butter on one slice and jelly on the other.
- Combine the ingredients by pressing the bread together and cutting the sandwich in half for easier handling.
Each step is clear and can be broken down further into simpler steps. The process is auditable, so if something goes wrong, it’s easy to pinpoint where the logic broke down. This turns language generation into structured, linear reasoning that mirrors how we train warfighters to think.
Now shift that logic to a warfighting mission. Imagine asking an AI system, “What is the best course of action given this enemy movement?” With chain of thought, the model might reason through: What’s the objective? What assets are available? What are the constraints? What threats are present? How do doctrine and rules of engagement (ROE) apply? What courses of action (COAs) are available, and what are the tradeoffs? This kind of structured reasoning is essential for building trustworthy outputs, especially when models are part of a kill chain.
From linear steps to decision graphs
Of course, not all decisions follow a clean, sequential path. In fact, real-world operations are rarely linear. Most warfighting decisions involve parallel processing, conditional logic, fallback options and context-specific adjustments. This is where web of logic becomes critical.
Web of logic is best understood as nodal decision-making. Instead of walking through a single sequence of steps, it treats each element of a complex decision as a node—a self-contained module that evaluates inputs applies logic, and either returns a decision or passes data to other nodes in the web. These nodes can operate in parallel or sequentially based on dependencies, and the entire structure forms a decision graph rather than a simple linear path.
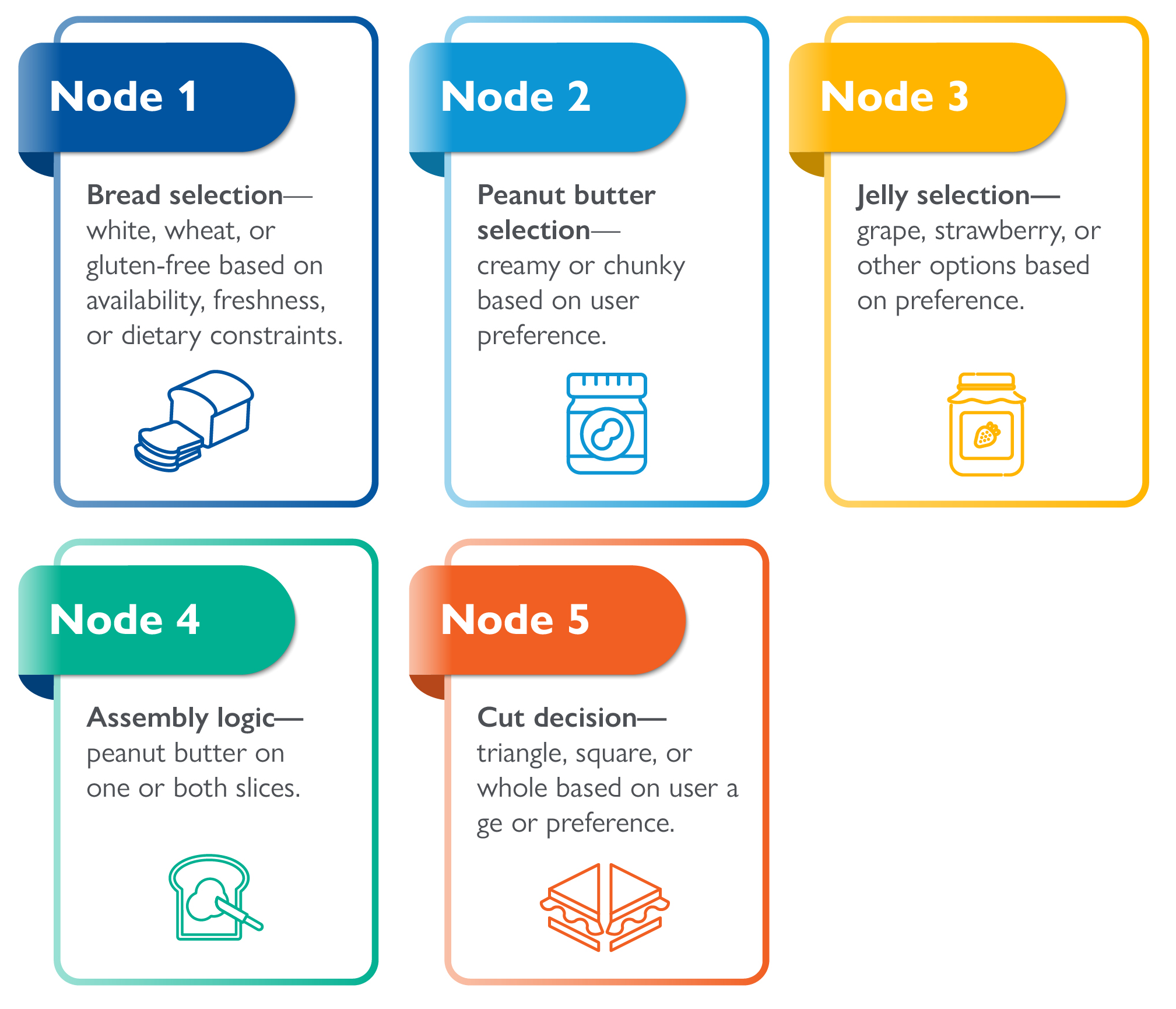
To understand the differences, let’s return to the PB&J example. Instead of one sequential process, in web of logic each decision point becomes its own module:
- Node 1: Bread selection — white, wheat, or gluten-free based on availability, freshness, or dietary constraints.
- Node 2: Peanut butter selection — creamy or chunky based on user preference.
- Node 3: Jelly selection — grape, strawberry, or other options based on preference.
- Node 4: Assembly logic — peanut butter on one or both slices.
- Node 5: Cut decision — triangle, square, or whole based on user age or preference.
Each node operates semi-independently and can be executed in a flexible order, guided by constraints, context, and user intent. The final product is shaped by a graph of modular decisions. It’s non-deterministic yet auditable and understandable. The whole thing is based around a desired output: the ideal PB&J.
Now replace sandwiches with Intelligence, Surveillance and Reconnaissance (ISR) workflows or targeting COAs, and the analogy becomes operational:
- Node 1: Sensor analysis — Classifies sensor readings as inputs to the model.
- Node 2: ROE constraints — Identifies relevant ROE constraints.
- Node 3: Target selection — Matches targets to available fires.
- Node 4: Deconfliction — Handles deconfliction and asset pairing.
- Node 5: COA generation — Generates course of action.
- Node 6: Route for review — Distributes results to appropriate endpoints.
Both chain of thought and web of logic use what raw LLMs fundamentally lack: discipline. By design, LLMs are generalists. They give good answers to well-crafted questions on mainstream topics. But in the ambiguous world of warfighting problem sets, generative reasoning needs structure. These prompting methods provide that structure without needing to retrain or rebuild the underlying model. They’re lightweight yet powerful tools for controlling behavior and ensuring alignment with reasoning under pressure.
Ultimately, these methods help build trust. When commanders see an answer broken down correctly step by step and can trace it back to the underlying doctrine or source document, they can interrogate the logic that led to the recommendation.
Why RAG-R works in national security and intelligence settings
While commercial models struggle under the weight of security constraints, data drift and mission variability, the RAG framework aligns with how warfighting and intelligence operations function.
The RAG framework can be deployed inside secure, air-gapped environments—Secret Internet Protocol Router Network (SIPR), Joint Worldwide Intelligence Communications System (JWICS) intelligence community enclaves, tactical edge servers, and closed-loop training or testing ranges. Since the framework is modular, containerized and decoupled, there’s no requirement for cloud-based inference or remote API calls. The retrieval pipeline, the document store and the reasoning model can all run locally, within the enclave boundary.
The RAG framework adapts to changing inputs. In a traditional LLM or fine-tuned model, updating the system to account for new knowledge requires retraining, which can take weeks or months. With RAG, the model remains fixed, and only the underlying document index changes. There’s no need to “teach” the model. All that’s required is to supply it with updated source material.
That agility extends to user-specific and mission-specific configurations. A CENTCOM J2 cell and a PACFLT operations center don’t need the same corpus of documents. Nor do they operate under the same assumptions, platforms or threat environments. With RAG, each mission enclave can tailor its retrieval pool and system prompting for what’s operationally relevant.
Because the RAG framework separates reasoning from knowledge, it also enables governance and control in a way that other approaches struggle to support. The documents included in the retrieval index are chosen by mission owners. Access to those documents can be scoped via existing role-based access control (RBAC) or attribute-based access control (ABAC) policies and tied to intelligence community governance. Markings, caveats and dissemination rules can be enforced at the retrieval layer, ensuring that users only see what they’re cleared to see.
Mission-centric AI
At this point, the strategic calculus should be clear: the Department of War and the Intelligence Community need artificial intelligence that is operationally grounded, securely deployable, and mission-aligned by deliberate design. No matter how flashy or well-funded, general-purpose chatbots and frontier language models simply aren’t enough.
The RAG framework offers a clear methodology to bring the AI to the mission, rather than forcing the mission to conform to the AI.
It respects the information environment (classified, fragmented, fast moving) and gives operators the ability to interrogate, verify and adjust as necessary. It empowers decision-makers to use AI as a decision accelerator—giving minutes back to mission.
The RAG framework doesn’t replace the human-in-the-loop. It enhances human strengths by reducing cognitive load and organizing the firehose of information flow into a narrow, precise stream. It gives time back to decision-makers rather than adding further headaches and complexities.
The future belongs not to those with the most powerful models, but to those with the most resilient infrastructure for AI lifecycle management and mission alignment. RAG-R is how we get there—by turning probabilistic language models into structured, explainable, and operationally responsible decision aids.
Ready to start building your AI infrastructure and AI advantage with SAIC? Reach out to learn more about how we’re operationalizing RAG-R for warfighting and intelligence missions.


